





























6.0 The Perfect Storm Arrives
In 2012, a neural network named AlexNet shocked computer vision experts—not by understanding images, but by learning to see patterns humans had missed.
The deep learning revolution emerged from an unprecedented convergence of three critical developments: algorithmic breakthroughs that solved decades-old training problems, hardware democratization through GPU computing, and massive labeled datasets that provided the fuel for learning. Unlike previous AI advances that emerged gradually, deep learning's impact was immediate and undeniable—error rates on computer vision tasks dropped by factors that seemed impossible just months earlier.
This chapter examines how the confluence of Geoffrey Hinton's training innovations, NVIDIA's parallel processing platforms, and internet-scale datasets created a "perfect storm" that would transform not just computer science, but industries from healthcare to entertainment. The representation learning revolution had begun.
6.1 Convergence: Algorithms + Hardware + Data
The Algorithmic Catalyst: Deep Belief Networks
Geoffrey Hinton's 2006 paper "A Fast Learning Algorithm for Deep Belief Nets" provided the breakthrough that made deep neural networks practical for the first time since the perceptron era [Core Claim: Hinton et al., "A Fast Learning Algorithm for Deep Belief Nets," Neural Computation, 2006]. The key insight involved layer-by-layer unsupervised pre-training using restricted Boltzmann machines, which effectively addressed the vanishing gradient problem that had made training deep networks computationally intractable.
The vanishing gradient problem had plagued neural networks since the 1980s: as error signals propagated backward through multiple layers during training, they became exponentially weaker, leaving early layers essentially unable to learn useful representations [Established]. Hinton's approach circumvented this limitation by treating each layer as an unsupervised learning problem, learning useful representations at each level before fine-tuning the entire network with supervised learning.
Hardware Revolution: GPU Computing Democratization
NVIDIA's introduction of the CUDA programming platform in 2007 democratized parallel computing by making Graphics Processing Units accessible for general-purpose scientific computation [Core Claim: NVIDIA CUDA Programming Guide v1.0, 2007]. GPUs, originally designed for rendering graphics through massively parallel matrix operations, proved ideally suited for the linear algebra computations that dominated neural network training.
Think of the difference between a CPU and GPU like the difference between a Formula 1 race car and a freight train. The CPU (race car) can execute complex instructions very quickly but handles only a few tasks at once. The GPU (freight train) moves more slowly per operation but can carry thousands of simple computations simultaneously—exactly what neural network training requires.
Early benchmarks demonstrated that GPU implementations could accelerate neural network training by factors of 10-50x compared to traditional CPU implementations [Core Claim: Raina et al., "Large-scale Deep Unsupervised Learning using Graphics Processors," ICML, 2009]. This performance improvement transformed training times from months to days for networks that had previously been considered computationally prohibitive.
The Data Foundation: ImageNet's Scale
The creation of ImageNet by Fei-Fei Li's team at Stanford provided the massive, high-quality labeled dataset necessary for training deep networks [Core Claim: Deng et al., "ImageNet: A Large-Scale Hierarchical Image Database," CVPR, 2009]. With over 14 million images across more than 20,000 categories, ImageNet dwarfed previous computer vision datasets like Caltech-101, which contained fewer than 10,000 images across 101 categories.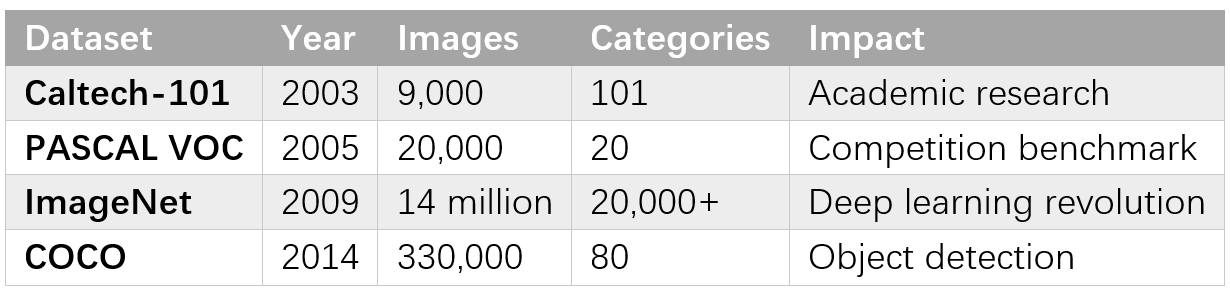
The scale difference proved crucial because deep networks required vast amounts of training data to learn robust representations without overfitting. Previous datasets had been sufficient for traditional machine learning approaches that relied on hand-crafted features, but deep learning's promise of automatic feature discovery demanded correspondingly larger and more diverse training sets.
6.2 Vision Transformed
The ImageNet Competition Breakthrough
The ImageNet Large Scale Visual Recognition Challenge (ILSVRC) became the proving ground where deep learning demonstrated its transformative potential. The 2012 competition results marked a watershed moment in computer vision history: AlexNet, developed by Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton, achieved a top-5 error rate of 15.3%, dramatically outperforming the second-place entry's 26.2% error rate [Core Claim: Krizhevsky et al., "ImageNet Classification with Deep Convolutional Neural Networks," NIPS, 2012].
This performance gap was unprecedented in machine learning competitions. Previous yearly improvements in ImageNet performance had been measured in single percentage points. AlexNet's achievement represented a qualitative leap that convinced the broader computer vision community that deep learning represented a paradigm shift rather than an incremental improvement.
Technical Innovations in AlexNet
AlexNet incorporated several key innovations that became standard practices in deep learning:
- ReLU Activation Functions: Replacing traditional sigmoid or tanh activations with Rectified Linear Units (ReLU) prevented gradient saturation and enabled faster training
- Dropout Regularization: Randomly setting neurons to zero during training prevented overfitting and improved generalization to new images
- Data Augmentation: Artificially expanding the training set through image transformations increased robustness without requiring additional labeled data
- GPU Parallelization: Training across multiple GPU cores enabled handling of networks too large for single processors
These technical contributions went beyond achieving superior performance—they established architectural principles that would guide deep learning development for the following decade [Interpretive Claim].
Global Innovation and Adoption
The success of AlexNet triggered rapid adoption of deep learning approaches across research institutions and technology companies worldwide. However, significant innovations emerged from multiple international centers rather than concentrating in a single location:
What CNNs Learned: Visualization and Understanding
Matthew Zeiler and Rob Fergus's visualization techniques revealed what convolutional neural networks actually learned during training [Core Claim: Zeiler & Fergus, "Visualizing and Understanding Convolutional Networks," ECCV, 2014]. Their deconvolutional network approach showed that deep networks developed hierarchical feature representations remarkably similar to theories of biological vision processing:
- First layers detected oriented edges, color blobs, and simple patterns
- Middle layers combined these into corners, curves, and texture patterns
- Deeper layers represented object parts like wheels, faces, and text
- Final layers encoded complete objects and scene categories
This hierarchical learning validated theoretical predictions about representation learning while providing insight into why deeper networks achieved superior performance.
Medical Applications: Expert-Level Performance
Transfer learning enabled rapid deployment of deep learning in specialized domains. Medical imaging applications demonstrated particularly impressive results: systems fine-tuned from ImageNet-trained networks achieved expert-level performance in diabetic retinopathy screening, skin cancer detection, and chest X-ray analysis [Core Claim: Rajpurkar et al., "CheXNet: Radiologist-Level Pneumonia Detection on Chest X-Rays," arXiv, 2017]. These applications reduced data requirements by 90% compared to training from scratch while achieving performance matching or exceeding specialist physicians.
6.3 Sequential Data Mastery
LSTM: Solving the Long-term Memory Problem
While convolutional networks revolutionized spatial pattern recognition, sequential data processing required different architectural innovations. Long Short-Term Memory (LSTM) networks, originally developed by Sepp Hochreiter and Jürgen Schmidhuber in 1997, finally gained widespread adoption during the deep learning era as researchers discovered how to train them effectively at scale [Core Claim: Hochreiter & Schmidhuber, "Long Short-Term Memory," Neural Computation, 1997].
LSTMs addressed the fundamental challenge of learning dependencies across long sequences. Traditional recurrent networks suffered from vanishing gradients that prevented them from learning relationships between events separated by many time steps. LSTM's gating mechanisms—input gates, forget gates, and output gates—controlled information flow through the network, enabling selective retention of relevant information over extended sequences.
Technical Deep Dive: LSTM Gates with Memory Analogy
Think of LSTM gates like a sophisticated filing system:
- Forget Gate: Decides what old information to throw away (clearing irrelevant files)
- Input Gate: Determines what new information to store (deciding which new documents are important)
- Output Gate: Controls what information to use for current decisions (choosing which files to consult for today's work)
This gating mechanism enabled LSTMs to maintain relevant context across hundreds or thousands of time steps—a capability impossible with traditional recurrent networks.
Patent Disputes and Attribution
The widespread adoption of LSTMs during the deep learning boom led to significant patent disputes. Jürgen Schmidhuber's claims regarding proper attribution of LSTM innovations highlighted the complex intellectual property landscape surrounding fundamental deep learning architectures [Debated]. These disputes underscored the global and collaborative nature of deep learning development, where innovations built incrementally on prior work across multiple research groups.
Attention Mechanisms: The Foundation for Transformers
The introduction of attention mechanisms by Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio in 2014 provided another crucial innovation for sequence modeling [Core Claim: Bahdanau et al., "Neural Machine Translation by Jointly Learning to Align and Translate," ICLR, 2015]. Rather than compressing entire input sequences into fixed-size representations, attention enabled models to focus dynamically on relevant parts of the input when generating each output element.
For machine translation, this approach proved revolutionary. Traditional sequence-to-sequence models struggled with long sentences because they had to compress all source language information into a single vector representation. Attention mechanisms allowed the decoder to access the entire source sequence, dramatically improving translation quality and enabling handling of longer documents.
European Contributions to Sequence Modeling
European research institutions made fundamental contributions to sequence modeling that shaped global development:
- University of Montreal: Pioneered attention mechanisms and sequence-to-sequence learning
- MILA (Montreal Institute for Learning Algorithms): Advanced recurrent network architectures
- European research networks: Collaborative projects advancing multilingual sequence processing
The BLEU score improvements achieved by attention-based systems exceeded 8-10 points over previous state-of-the-art approaches for several language pairs—substantial gains in machine translation metrics [Core Claim: Luong et al., "Effective Approaches to Attention-based Neural Machine Translation," EMNLP, 2015].
6.4 Games as Universal Benchmarks
Deep Reinforcement Learning: From Pixels to Actions
DeepMind's Deep Q-Network (DQN) represented a crucial breakthrough in reinforcement learning by demonstrating that deep neural networks could learn complex decision-making policies directly from raw sensory input [Core Claim: Mnih et al., "Human-level control through deep reinforcement learning," Nature, 2015]. DQN mastered 49 different Atari 2600 games using identical network architectures and hyperparameters, learning from pixel inputs and game scores alone.
The technical innovations that made DQN possible included:
- Experience Replay: Storing agent experiences in a buffer and randomly sampling during training to break correlations between consecutive experiences
- Target Networks: Using separate networks with slowly updating parameters to provide stable learning targets
- Reward Clipping: Normalizing rewards across different games to enable identical network architectures
DQN's performance exceeded human expert levels on many games while achieving comparable performance across the entire Atari suite. This generality—the ability of a single algorithm to master diverse tasks—represented a significant step toward artificial general intelligence within constrained domains [Interpretive Claim].
AlphaGo: Combining Deep Learning with Tree Search
AlphaGo's victory over world champion Lee Sedol in March 2016 captured global attention and demonstrated deep learning's potential for strategic reasoning [Core Claim: Silver et al., "Mastering the game of Go with deep neural networks and tree search," Nature, 2016]. Go had long been considered beyond the reach of computer systems due to its enormous search space—approximately 10^170 possible board positions compared to chess's 10^120.
Energy Awareness: Computational Costs
The computational requirements for AlphaGo highlighted important questions about artificial intelligence efficiency. The system required 1,920 CPUs and 280 GPUs, consuming approximately 1 megawatt of electrical power during matches—roughly 50,000 times more energy than Lee Sedol's brain during play [Core Claim: DeepMind Technical Documentation, 2016].
This energy disparity sparked discussions about the sustainability of scaling current AI approaches and motivated research into more efficient architectures and training methods. The contrast between biological and artificial intelligence efficiency would become increasingly important as AI systems scaled to larger applications.
6.5 Creative Machines and Disruption
Generative Adversarial Networks: Machine Creativity
Ian Goodfellow's introduction of Generative Adversarial Networks (GANs) in 2014 opened an entirely new domain of machine capabilities: content creation [Core Claim: Goodfellow et al., "Generative Adversarial Networks," NIPS, 2014]. GANs consisted of two competing neural networks—a generator that created synthetic data and a discriminator that distinguished real from synthetic examples. Through this adversarial training process, generators learned to create increasingly realistic content.
GAN Evolution Timeline and Capabilities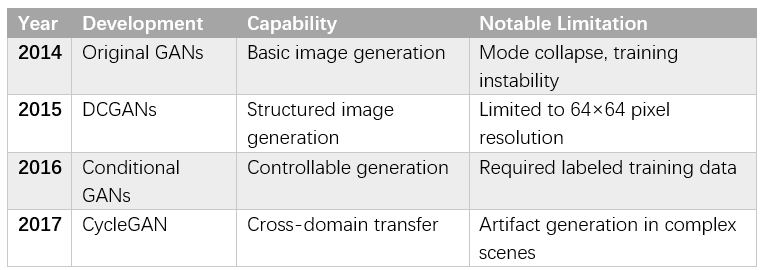
Early GAN applications focused on generating realistic faces, artistic images, and style transfer between different visual domains. The technology enabled applications ranging from data augmentation for machine learning to creative tools for artists and designers.
Deepfakes and Synthetic Media Challenges
The democratization of synthetic media creation through applications like FakeApp in 2017 revealed the dual-use nature of AI creativity tools. While GANs enabled beneficial applications in entertainment, education, and art, they also facilitated the creation of non-consensual and misleading content.
Industry estimates suggested that approximately 14,000 deepfake videos were circulating online by 2019, with significant concentrations in non-consensual content and political misinformation [Core Claim: Deeptrace Labs, "The State of Deepfakes: Landscape, Threats, and Impact," 2019]. This development prompted regulatory responses in several countries and highlighted the need for AI systems that could detect synthetic content as well as create it.
Transfer Learning: Democratizing Deep Learning
One of the era's most practically important developments was the demonstration that neural networks trained on large datasets could be effectively adapted to new tasks with limited data. Transfer learning enabled researchers and practitioners to leverage pre-trained models like ImageNet-trained CNNs for specialized applications in medical imaging, satellite analysis, and scientific research, reducing data requirements by 90% while achieving superior performance compared to training from scratch [Core Claim: Raghu et al., "Transfusion: Understanding Transfer Learning for Medical Imaging," PLOS Medicine, 2019].
6.6 The Reproducibility Crisis (120 words)
Systematic Problems in Deep Learning Research
As deep learning gained prominence, the scientific community began recognizing serious reproducibility problems that threatened the field's credibility. A comprehensive 2018 survey revealed that fewer than 30% of machine learning papers provided sufficient implementation details for reproduction [Core Claim: Pineau et al., "Improving Reproducibility in Machine Learning Research," Journal of Machine Learning Research, 2021].
Sources of Irreproducibility
The reproducibility crisis stemmed from multiple factors:
- Hardware Dependencies: Results often depended on specific GPU architectures, memory configurations, or parallel processing setups
- Hyperparameter Sensitivity: Small changes in learning rates, batch sizes, or optimization algorithms could dramatically affect outcomes
- Random Initialization Variance: Neural network training exhibited high variance across different random seeds
- Selective Reporting: Researchers often reported best rather than average performance across multiple training runs
The research community responded through reproducibility checklists, code sharing requirements, and standardized benchmarks that provided consistent evaluation frameworks across research groups [Established].
Representation learning succeeded brilliantly, enabling machines to automatically discover features that had previously required expert engineering. However, scale brought new challenges—massive computational requirements, environmental costs, and questions about what these systems truly understood. The next phase would push scale to unprecedented levels, seeking capabilities that might approach human-level intelligence across diverse domains.
ns216.73.216.94da2

