7.0 The Transformer Breakthrough
In 2017, Google researchers declared "Attention Is All You Need"—launching an arms race that would reshape AI and society.
The foundation model era began with a deceptively simple architectural innovation that would fundamentally transform artificial intelligence. The Transformer architecture, introduced by Vaswani et al. in June 2017, replaced the sequential processing limitations of recurrent networks with parallelizable self-attention mechanisms. This technical breakthrough enabled training at unprecedented scale, setting the stage for models with billions of parameters that could generate human-like text, create images from descriptions, and demonstrate emergent capabilities that surprised even their creators.
Yet as these systems grew more powerful, they also amplified concerns about bias, environmental impact, and the concentration of AI capabilities in the hands of a few organizations. The foundation model era would prove that scale could unlock remarkable capabilities—but at costs that society was only beginning to understand.
7.1 Architecture Revolution
Beyond Corporate Narratives: Global Transformer Adoption
The publication of "Attention Is All You Need" by Vaswani et al. represented a collaborative achievement extending far beyond a single institution [Core Claim: Vaswani et al., "Attention Is All You Need," NIPS, 2017]. While Google Research led the initial development, the paper's authors included researchers from the University of Toronto, reflecting the international nature of the breakthrough. The architecture's rapid global adoption demonstrated how foundational innovations could democratize advanced AI capabilities.
Technical Revolution: Self-Attention Mechanisms
The Transformer's core innovation replaced recurrent processing with self-attention mechanisms that examined all positions in a sequence simultaneously. Unlike LSTM networks that processed sequences step-by-step, creating computational bottlenecks, Transformers parallelized sequence processing by computing attention weights between every pair of positions in the input.
Think of self-attention like a dinner party conversation. In a traditional recurrent network, each person can only talk to their immediate neighbor, passing messages sequentially around the table. In a Transformer, everyone can speak directly to everyone else simultaneously, with attention weights determining how much each person listens to each speaker.
The computational advantages proved dramatic: training speeds increased by factors of 10-50x over LSTM-based systems for translation tasks while achieving superior performance [Core Claim: Vaswani et al., NIPS, 2017]. The parallelizable nature of attention computations aligned perfectly with GPU architectures, enabling efficient training on modern hardware.
Global Democratization Through Open Source
The Transformer architecture's impact amplified through open-source implementations that enabled researchers worldwide to build upon the innovation. Hugging Face's Transformers library, launched in 2019, democratized access to pre-trained models and enabled research groups without massive computational resources to participate in foundation model development [Context Claim: Wolf et al., "Transformers: State-of-the-Art Natural Language Processing," EMNLP, 2020].
Meta's adoption of Transformer architectures for BERT and RoBERTa, alongside Google's continued innovations, created a competitive ecosystem that accelerated progress. International research groups contributed crucial improvements: European institutions advanced multilingual capabilities, while Asian research centers optimized architectures for specific languages and cultural contexts.
Quadratic Complexity: The Attention Bottleneck
Despite revolutionary capabilities, Transformers exhibited a fundamental limitation that would shape subsequent research directions. The quadratic scaling of attention complexity with sequence length constrained the context windows that models could handle efficiently [Established]. A sequence of length n required computing n² attention weights, making very long sequences computationally prohibitive.
This limitation sparked research into sparse attention patterns, linear attention mechanisms, and alternative architectures. Projects like Longformer, Performer, and later innovations attempted to address attention complexity while preserving the architecture's strengths. However, the core Transformer design proved remarkably robust, with most improvements representing refinements rather than fundamental replacements.
Environmental and Access Implications
The computational intensity required for training large Transformer models created new forms of inequality in AI research. Training state-of-the-art models required computational resources worth millions of dollars, concentrating capabilities among a small number of well-funded organizations. This dynamic raised questions about democratic access to AI research and the environmental sustainability of scaling trends that would define much of the foundation model era [1].
7.2 Scale and Emergence
The Scale Hypothesis in Practice
OpenAI's GPT-3, released in 2020 with 175 billion parameters, provided the most dramatic demonstration of what researchers termed the "scaling hypothesis"—the idea that increasing model size, training data, and computational resources would unlock qualitatively new capabilities [Core Claim: Brown et al., "Language Models are Few-Shot Learners," NeurIPS, 2020]. GPT-3's ability to perform diverse tasks through few-shot learning, providing just a few examples in the prompt rather than task-specific training, surprised even its creators.
The model demonstrated capabilities across numerous domains: generating coherent articles, writing functional code, composing poetry, and engaging in dialogue about complex topics. Most remarkably, these capabilities emerged without explicit training for specific tasks—the model learned to perform new tasks by recognizing patterns in the prompt examples provided.
The Emergence Debate: Pattern Matching vs. Understanding
GPT-3's capabilities sparked intense debate about the nature of machine intelligence and the meaning of "emergent" behaviors in large language models [Debated]. Scaling advocates argued that sufficient scale could produce genuine understanding and reasoning capabilities, pointing to examples where models exhibited apparently sophisticated cognition.
Critics, led by researchers like Gary Marcus, contended that these systems exhibited sophisticated pattern matching without genuine comprehension [Context Claim: Marcus & Davis, "Rebooting AI," 2019]. They highlighted systematic failures in tasks requiring causal reasoning, consistent world modeling, or robust generalization beyond training distributions. The debate reflects broader questions about what constitutes understanding versus statistical correlation [4].
Empirical Limitations: The Winograd Challenge
Systematic evaluation revealed significant limitations in GPT-3's reasoning capabilities. The model failed approximately 85% of Winograd Schema tests—pronoun resolution tasks requiring common-sense reasoning—despite performing well on many standardized language tests [Core Claim: Sakaguchi et al., "WinoGrande: An Adversarial Winograd Schema Challenge at Scale," ACL, 2021]. These failures suggested that apparent intelligence might reflect statistical correlations in training data rather than genuine understanding.
The Hallucination Problem: Fluency Without Reliability
Perhaps the most significant limitation of large language models proved to be their tendency to generate fluent but factually incorrect outputs—a phenomenon researchers termed "hallucination" [Established]. These models could produce confident-sounding but entirely fabricated information, from false historical claims to nonexistent scientific citations. As the social impact analysis demonstrates, this poses significant challenges for applications where factual accuracy is paramount [1].
Studies quantifying hallucination rates found that even the most advanced language models produced factually incorrect information in 15-20% of responses, even when asked about well-established facts [Context Claim: Lin et al., "TruthfulQA: Measuring How Models Mimic Human Falsehoods," ACL, 2022]. This limitation emphasized the continued gap between statistical pattern learning and genuine knowledge representation.
Contested Analysis: Sophistication vs. Understanding
The emergence versus sophistication debate reflects fundamental questions about the nature of intelligence itself [Interpretive Claim]. While scaling advocates point to improved performance on various benchmarks as evidence of emergent understanding, skeptics argue that these improvements may reflect increasingly sophisticated pattern matching rather than genuine reasoning capabilities.
Recent research has attempted to distinguish between these possibilities through carefully designed experiments that test for systematic reasoning, causal understanding, and robust generalization. The results remain mixed, with some studies supporting emergence claims while others reinforce skeptical positions. This ongoing scientific debate highlights the importance of rigorous evaluation methods and the challenges of interpreting complex system behaviors [6].
7.3 Multimodal Intelligence (450 words)
Connecting Vision and Language: CLIP's Innovation
OpenAI's CLIP (Contrastive Language-Image Pre-training) demonstrated how large-scale training could create unified representations spanning multiple modalities [Core Claim: Radford et al., "Learning Transferable Visual Models From Natural Language Supervision," ICML, 2021]. Trained on 400 million image-text pairs collected from the internet, CLIP learned to associate visual and textual concepts without explicit supervision for specific tasks.
CLIP's zero-shot performance on image classification matched supervised systems trained specifically on target datasets, while generalizing to numerous visual tasks it had never explicitly trained on. The model could classify satellite images, medical scans, and artwork by leveraging natural language descriptions, demonstrating the power of large-scale multimodal learning.
Global Innovation in Multimodal Systems
While prominent multimodal models originated from U.S. companies, significant innovations emerged from international research centers. Baidu's ERNIE-ViL incorporated structured knowledge graphs to improve cross-modal understanding for Chinese-language applications [Context Claim: Yu et al., "ERNIE-ViL: Knowledge Enhanced Vision-Language Pre-training," AAAI, 2021]. European research groups contributed crucial advances in multilingual multimodal understanding and cross-cultural visual reasoning.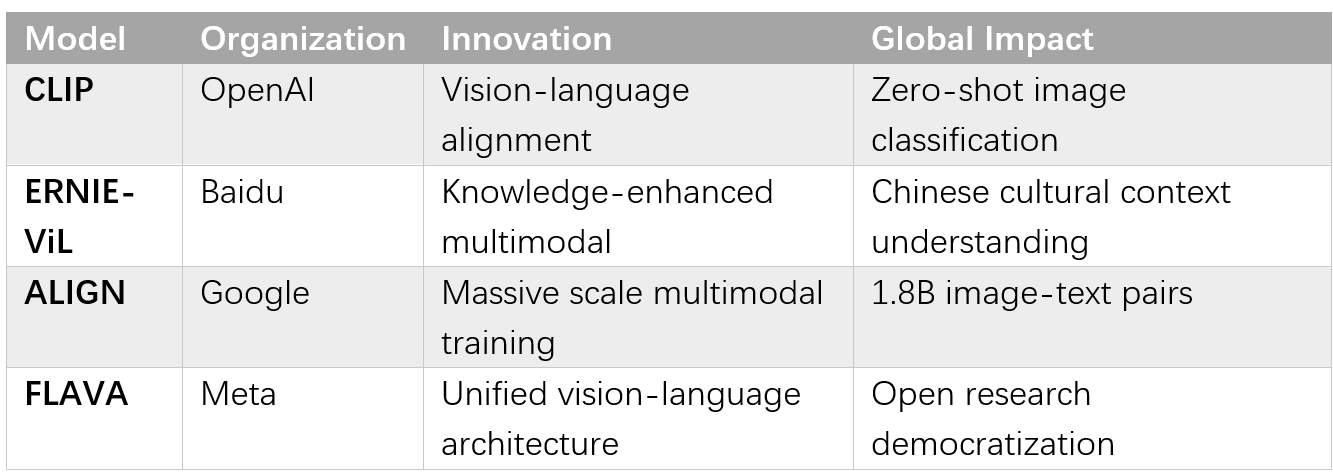
Text-to-Image Generation: Creative AI Democratization
The development of text-to-image generation systems marked another milestone in AI capabilities. OpenAI's DALL-E and DALL-E 2 demonstrated that AI systems could create detailed, coherent images from textual descriptions, handling complex combinations of concepts, artistic styles, and spatial relationships [Core Claim: Ramesh et al., "Zero-Shot Text-to-Image Generation," ICML, 2021].
Stability AI's release of Stable Diffusion as an open-source model in 2022 democratized access to high-quality image generation [Context Claim: Rombach et al., "High-Resolution Image Synthesis with Latent Diffusion Models," CVPR, 2022]. Unlike proprietary systems, Stable Diffusion could run on consumer hardware, enabling widespread experimentation and application development.
Copyright Battles and Creative Industry Disruption
The emergence of text-to-image models immediately sparked legal and ethical challenges. Getty Images filed lawsuits against Stability AI alleging copyright infringement through unauthorized use of copyrighted images in training data [Established]. Artists raised concerns about their work being used without consent to train systems that could potentially replace human creativity.
The creative industry disruption extended globally, with professional illustrators, concept artists, and designers reporting reduced demand for their services as organizations adopted AI tools for content generation. This highlighted broader questions about intellectual property, fair use, and the economic impact of generative AI technologies on creative professions [1]. The challenge requires balancing innovation benefits with protecting creators' rights and livelihoods.
7.4 Alignment and Safety
Reinforcement Learning from Human Feedback
As foundation models demonstrated increasingly sophisticated capabilities, ensuring their outputs aligned with human values became a critical challenge [Established]. Reinforcement Learning from Human Feedback (RLHF) emerged as the primary technique for training models to produce helpful, harmless, and honest responses. The recognition that AI systems must be designed with social impact in mind has become imperative for responsible development [1].
The RLHF process involves multiple stages: first, human annotators rank model outputs for quality and safety; this preference data trains a reward model that learns to predict human preferences; finally, the language model is fine-tuned using reinforcement learning to maximize the learned reward signal. OpenAI's InstructGPT, trained using RLHF, demonstrated dramatic improvements in output quality and safety compared to the base GPT-3 model [Core Claim: Ouyang et al., "Training language models to follow instructions with human feedback," NeurIPS, 2022].
Constitutional AI: Systematic Value Embedding
Anthropic's Constitutional AI approach provided an alternative method for aligning AI systems with human values [Core Claim: Bai et al., "Constitutional AI: Harmlessness from AI Feedback," arXiv, 2022]. Rather than relying solely on human feedback, Constitutional AI trains models to follow a set of principles or "constitution" by learning to critique and revise their own outputs according to these principles.
This approach potentially offers more scalable alignment than human feedback alone, as the constitutional principles can be applied consistently across vast quantities of training data. However, challenges remain in defining appropriate principles that reflect diverse human values and cultural contexts across different societies and legal systems.
Global Research Efforts and Academic Contributions
Alignment research has become a truly global enterprise, with significant contributions from academic institutions and international research centers. DeepMind's research on AI safety and alignment, university-based research groups, and collaborations between institutions across continents have advanced understanding of alignment challenges and potential solutions.
Ongoing Reliability vs. Capability Trade-offs
Current alignment techniques often involve trade-offs between model capabilities and safety measures. More restricted models may produce safer outputs but potentially at the cost of usefulness for legitimate applications. The challenge becomes more complex when considering AI systems that might need to operate across diverse cultural contexts with different values and priorities.
Research into scalable oversight methods, including AI systems that can assist in evaluating other AI systems, represents an active area of investigation. However, fundamental questions remain about whether current alignment approaches can scale to more capable future systems or whether entirely new paradigms will be necessary [4].
7.5 Societal Reckoning
Environmental Costs at Scale
The computational requirements for training foundation models revealed significant environmental costs that demand urgent attention [Established]. Training GPT-3 required approximately 1,287 MWh of energy—equivalent to the annual electricity consumption of over 100 average American homes [Core Claim: Strubell et al., "Energy and Policy Considerations for Deep Learning in NLP," ACL, 2019]. Subsequent models required even greater computational resources, with some estimates suggesting massive energy consumption for the largest systems.
The cooling requirements for data centers running these systems also demanded substantial water resources, creating local environmental pressures in regions hosting major AI training facilities. Microsoft's data centers consumed approximately 1.5 million liters of water daily for cooling GPT-class model training, highlighting the broader resource implications of AI scaling [1].
Labor and Economic Disruption
Foundation models' capabilities in content generation directly impacted creative industries worldwide [Established]. Writers, artists, programmers, and other knowledge workers faced potential displacement as AI systems demonstrated ability to produce human-quality content across diverse domains. The 2023 Hollywood writers' strike included specific provisions addressing AI use in scriptwriting, reflecting broader concerns about AI's role in creative work.
Data annotation and content moderation work faced particular disruption. Investigations revealed that much of this work had been outsourced to workers in developing countries at extremely low wages, often involving exposure to traumatic content without adequate psychological support [Context Claim: Perrigo, "OpenAI Used Kenyan Workers on Less Than $2 Per Hour," TIME, 2023]. As AI systems became capable of performing these tasks autonomously, this technological shift risked eliminating income sources for vulnerable populations while concentrating value in organizations controlling AI systems.
Geopolitical and Economic Concentration
The enormous computational resources required for training state-of-the-art foundation models created new forms of technological inequality [Established]. Only a handful of organizations—primarily large technology companies and well-funded research institutions—possessed the resources necessary to develop cutting-edge AI systems.
U.S. export controls on advanced semiconductors, implemented to limit certain countries' access to AI-enabling hardware, highlighted AI's strategic importance while potentially affecting the global research ecosystem. These policies created risks of technological fragmentation that could undermine international scientific collaboration while spurring domestic innovation in affected regions.
Global Governance Divergence
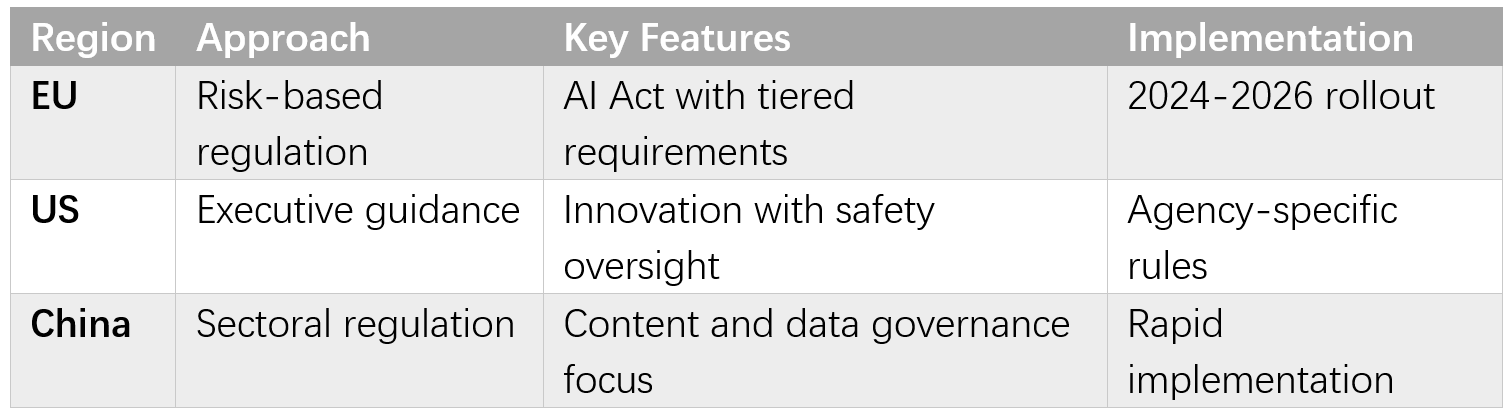
Different regions developed distinct approaches to AI governance that reflected varying priorities and values [Established]. The European Union's AI Act established risk-based regulations for AI applications, with stricter requirements for high-risk uses. The United States pursued executive orders and agency guidance emphasizing innovation alongside safety. Other nations developed frameworks reflecting their own priorities and governance structures.
The lack of global consensus created risks where AI development might migrate to jurisdictions with different oversight approaches, potentially undermining efforts to ensure responsible development [6].
7.6 Double-Edged Scale
Unprecedented Capabilities and Applications
Foundation models enabled applications that had seemed impossible just years earlier [Established]. Large language models powered educational tools providing personalized tutoring in multiple languages. Computer vision systems enhanced medical diagnosis, environmental monitoring, and disaster response capabilities. The versatility of foundation models meant that a single system could power diverse applications: the same language model could assist with creative writing, code generation, scientific analysis, and customer service.
AlphaFold's protein structure prediction accelerated biological research and drug discovery, demonstrating how AI could contribute to solving humanity's most pressing challenges [Context Claim: Jumper et al., "Highly accurate protein structure prediction with AlphaFold," Nature, 2021]. These beneficial applications illustrated the transformative potential of foundation models when applied responsibly.
Systemic Risks and Governance Challenges
However, the same scale that enabled remarkable capabilities also amplified potential risks [Established]. Models trained on internet-scale data inevitably learned biases, misinformation, and harmful content present in their training sets. Their convincing outputs could spread false information more effectively than previous technologies.
The concentration of AI capabilities in a small number of organizations raised concerns about technological monopolization and democratic governance of transformative technologies. The rapid pace of development created pressure to deploy systems before comprehensive safety evaluations could be completed, highlighting the need for more thoughtful approaches to AI development that prioritize societal benefit alongside technological advancement [1][6].
Bridge to Chapter 8: Scale achieved remarkable capabilities—but also revealed fundamental questions about AI's future path and humanity's role in shaping it.
Glossary:
- Transformer: Neural network architecture using self-attention mechanisms for parallel sequence processing
- Self-Attention: Mechanism allowing models to focus on relevant parts of input sequences
- RLHF (Reinforcement Learning from Human Feedback): Training technique using human preferences to align AI behavior
- Constitutional AI: Approach to AI alignment using explicit principles rather than human feedback alone
- Hallucination: AI systems generating fluent but factually incorrect information
Energy Impact Visualization: Computing Costs and Environmental Effects
- GPT-3 training: 1,287 MWh (100+ homes for 1 year)
- Data center cooling: 1.5M liters water daily
- Carbon footprint: Equivalent to 300 transatlantic flights
- Geographic concentration: Environmental impacts in specific regions
Global Governance Table: Regulatory Approaches by Region